原文连接: http://gameprogrammingpatterns.com/flyweight.html
Flyweight 模式
雾气散去,壮观的原始森林展现在我们面前。古老的铁杉,不尽其数。像一座塔尖林立的绿色教堂。在巨大的树干之间,你只有拉开一定距离才能辨认出这是一个巨大的森林。
这是作为游戏开发者梦想的世外桃源般的设计,而这种场景往往因为一个设计模式的运用而变为现实。这个模式的名字就是再低调不过的:Flyweight(被很多书根据意思翻译为享元)。
化木为林
我可以用轻描淡写的几句话描述一个无边森林,但是在一个实时游戏中实现它就是另一回事了。当你看到一个森林满屏都是树木的时候,在图形程序员眼里,他们是数以百万计的面片,这些面片必须每隔1/60秒就被塞进GPU一次。
我们说有数千棵树,每棵树又是由数千个面片的细节组成。就算你有足够的内存存储这些描述数据,在渲染时,这些数据也要通过总线从CPU送达到GPU中。
每棵树都有如下的一些相关的数据:
* 用于定义树干、枝杈、绿色植物的网格面片。
* 树皮和树叶的贴图。
* 在森林中的位置和朝向。
* 用于微调的参数如大小、色彩等等,让每一棵树看起来有些不同。
如果用代码写出来,我们得到如下结构:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class Tree { private: Mesh mesh_; Texture bark_; Texture leaves_; Vector position_; double height_; double thickness_; Color barkTint_; Color leafTint_; }; |
这将是很大的一堆数据,并且模型和贴图也特别大。整个森林的数据太大了,我们无法在一帧内将这些数据传送给GPU。幸运的是有一个传统的解决办法。
关键点是森林里虽然有很多树,但是这些树看起来长得都差不多。他们完全可以使用相同的模型和贴图。这就意味着所有树实例中有很大一部分是相同的。

我们可以试着把这些对象分成两份。首先,我们把所有树共有的数据搬到一个单独的类中:
|
1 2 3 4 5 6 7 |
class TreeModel { private: Mesh mesh_; Texture bark_; Texture leaves_; }; |
游戏中只需要一个这样的对象,因为没有必要在内存中把相同的模型和贴图保存上千份。然后,游戏中每一棵树的实例保存一份对TreeModel的引用。这样,Tree这个类中就只剩下了这些个性化的数据了。
|
1 2 3 4 5 6 7 8 9 10 11 |
class Tree { private: TreeModel* model_; Vector position_; double height_; double thickness_; Color barkTint_; Color leafTint_; }; |
你可以把它想象成这样:
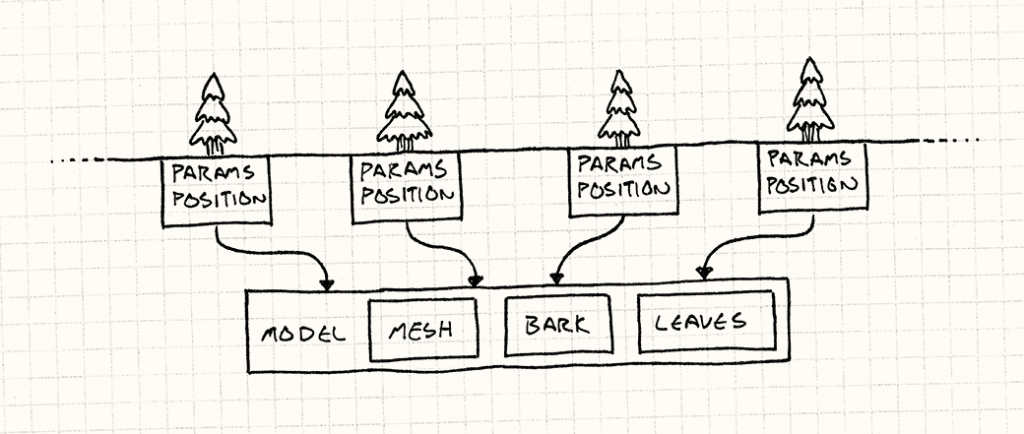
这样就很好的解决了在内存中的存储问题,但是对渲染于事无补。在森林被画到屏幕上之前,它必须要先进入GPU,我们需要把共享的资源展开成显卡能够识别的格式。
一千个实例
为了使我们传入GPU的数据量最小化,我们希望能够传入共享的数据——TreeModel一次。然后,分别把每一棵树的独有数据如位置、颜色、大小穿进去。最后我们告诉GPU,用这一个模型渲染所有的实例。
幸运的是,现在的图形API和显卡都已经支持这种方式了。具体的细节已经超出了本书的讨论范围,但是Direct3D和OpenGL都可以使用叫做instance rendering的技术实现。
这两个平台提供的API中,你需要提供两个数据流。第一个是将被渲染多次的公用数据块——我们例子中的模型和贴图。第二个数据流包含了一个实例列表以及它们的参数,它们可以区分每一次对第一个数据流的绘制结果。经过一次绘制,整个森林就长出来了。
Flyweight模式
现在我们掌握了一个实实在在的例子,我可以来演练一下这个设计模式。Flyweight,就像它的名字一样,主要适用用于我们有大量的对象需要减肥的时候。
通过instance rendering,不再占用过多的内存,就像不再占用过多的总线传送时间一样。其基本思路是一致的。
这个模式通过将一个对象的数据分成两类来解决问题。第一类不是单个实例个性化的数据,他们可以在所有实例间共享。GOF把这类数据叫做固有属性,但我更喜欢称之为上下文无关。在这个例子里,就是那些树的几何数据和贴图。
剩下的数据就是外部属性,这部分每一个实例都是独有的。这个例子中,就是树的位置、大小、颜色。就像上面那段代码展示的那样,这个模式通过在每一个出现的对象中共享固定属性,来达到节省内存的目的。
到现在为止,这个方法就像是最基本的资源共享,很难称之为一个设计模式。这可能使因为在这个例子中,我们很容易地分辨出哪一部分应该共享:TreeModel
我开始发现这个模式不同寻常(其实很聪明),是在一些共享对象不那么好定义的例子中。在这些情况下,你会感觉像是在玩分身魔术。让我展示另一个例子。
生根之地
游戏中我们还需要为这些树木制作生长的地方。它们可能是草丛、泥地、山峦、湖面、大河,或者你能想到的其他地形。我们制作的地形是基于分片的:大地的表面由大量小的片段组成。每一个片段都覆盖了一种类型的地面。
每一种地表类型都有一些影响游戏的属性:
* 决定玩家移动速度的移动消耗。
* 一个标明是否是水域的标识,它决定了这块地形可不可以过船。
* 一张渲染需要的贴图
由于游戏程序员对性能比较偏执,所以我们不可能把所有的这些属性保存在世界的每一个面片中。一个常用的方法是定义一个地形类型的枚举:
|
1 2 3 4 5 6 7 |
enum Terrain { TERRAIN_GRASS, TERRAIN_HILL, TERRAIN_RIVER // Other terrains... }; |
然后World类包含了大量这样的面片类型:
|
1 2 3 4 5 |
class World { private: Terrain tiles_[WIDTH][HEIGHT]; }; |
为了得到一个面片的相关信息,我们做这样的处理:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
int World::getMovementCost(int x, int y) { switch (tiles_[x][y]) { case TERRAIN_GRASS: return 1; case TERRAIN_HILL: return 3; case TERRAIN_RIVER: return 2; // Other terrains... } } bool World::isWater(int x, int y) { switch (tiles_[x][y]) { case TERRAIN_GRASS: return false; case TERRAIN_HILL: return false; case TERRAIN_RIVER: return true; // Other terrains... } } |
你明白,这是可以工作的,但是我觉得太丑了。我觉的移动消耗和是不是水域应该是与地形相关的数据,但这里并没有在代码中体现出来。更糟糕的是,一个地形相关的数据被分散到一堆其他函数里面。最理想的状况是把他们整合到一起,这个才是我们设计这些对象的目的。
如果我们有这样一个地形的定义就太棒了:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
class Terrain { public: Terrain(int movementCost, bool isWater, Texture texture) : movementCost_(movementCost), isWater_(isWater), texture_(texture) {} int getMovementCost() const { return movementCost_; } bool isWater() const { return isWater_; } const Texture& getTexture() const { return texture_; } private: int movementCost_; bool isWater_; Texture texture_; }; |
但是如果所有地形片段都有一个实例,那会带来我们不想承受的负担。如果你仔细观察这个类,你会发现其实里面并没有每一个地形片段独有的属性。在Flyweight中,所有的这些属性都应该被划为“固有属性”或者“上下文无关”。
考虑到这些,就没有理由创建多个Terrain对象了。每一块青草地的片段都跟其余的没有什么区别。我们不再使用地形枚举或者地形对象构成的网格了,我们用指向Terrain对象的指针构成网格来代替:
|
1 2 3 4 5 6 |
class World { private: Terrain* tiles_[WIDTH][HEIGHT]; // Other stuff... }; |
所有用相同地形的片段都指向同一个Terrain实例。
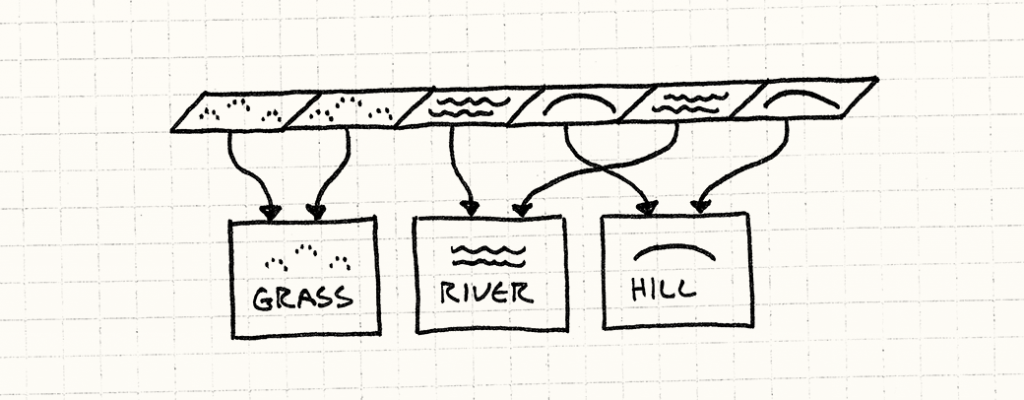
由于这些Terrain实例在多个场合中被用到,如果它使用的内存是动态申请的,那他们的生命周期管理就会比较复杂。在这里,我们就直接在World中存储了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class World { public: World() : grassTerrain_(1, false, GRASS_TEXTURE), hillTerrain_(3, false, HILL_TEXTURE), riverTerrain_(2, true, RIVER_TEXTURE) {} private: Terrain grassTerrain_; Terrain hillTerrain_; Terrain riverTerrain_; // Other stuff... }; |
然后我们可以这样把地面绘制出来:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
void World::generateTerrain() { // Fill the ground with grass. for (int x = 0; x < WIDTH; x++) { for (int y = 0; y < HEIGHT; y++) { // Sprinkle some hills. if (random(10) == 0) { tiles_[x][y] = &hillTerrain_; } else { tiles_[x][y] = &grassTerrain_; } } } // Lay a river. int x = random(WIDTH); for (int y = 0; y < HEIGHT; y++) { tiles_[x][y] = &riverTerrain_; } } |
现在我们再也不用通过World的方法来访问Terrain的数据了,我们可以直接得到Terrain对象:
|
1 2 3 4 |
const Terrain& World::getTile(int x, int y) const { return *tiles_[x][y]; } |
这样,World就不再跟Terrain的实现细节耦合在一起了。如果你想得到一个面片的属性,你可以直接从Terrain对象中得到:
|
1 |
int cost = world.getTile(2, 3).getMovementCost(); |
我们找回了使用真正对象的美好API,并且没有带来额外的消耗——一个指针一般不会比一个枚举更大。
性能如何
我说“一般”是因为对性能精打细算的人,会耿直地比较这种方法和使用枚举哪个性能更优。通过指针引用Terrain毕竟经过了一次间接寻址。为了能获得一块地形的属性如移动消耗,你必须先经过数组中的指针找到Terrain对象,然后才能在那里得到移动消耗。这种指针寻址可能会有高速缓存不命中的情况,造成运行变慢。
我们经常说,做优化的黄金法则是先验证。当今的计算机硬件在性能方面已经足够复杂,以至于它不再受单一因素影响。在我对本章的测试结果中,Flyweight并没有比枚举方式存在更多消耗。事实上,Flyweight反而明显地快一些。不过,这取决于其他部分在内存中是如何分布的。
我能够确信Flyweight的使用,不会造成失控。他在不带来额外开销的前提下,给了你一个使用面向对象形式的可能。如果你发现,代码里有大量的枚举或者switch语句,可以考虑用这种模式来代替。如果你担心效率问题,至少要在你将代码改的无法维护之前做一下测试。