网页渲染是浏览器内核最基本的任务,这一篇让我们研究一下,Chrome是如何利用GPU对这个过程进行加速的。
Webkit渲染基础
首先,来回顾一下Webkit内核的网页渲染流程。当Webkit拿到网页数据后,会根据网页结构生成DOM树,然后每一个DOM节点会生成对应的RenderObject,构成另一棵树RenderObject Tree。那些在同一个CSS转换坐标系下的节点,会被合并到一起,构成一个RenderLayer,像一些半透明的、独立CSS Filter的、Canvas、Video等有特殊渲染需求的RenderObject会生成单独的RenderLayer。关系如下图:
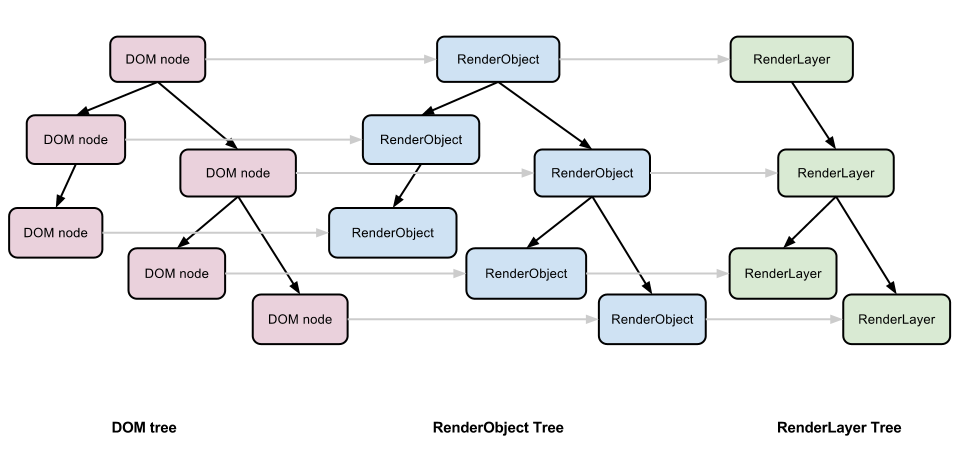
RenderLayer节点会将它所有的子节点分成两个列表,分别根据Z序分成了高于父节点和低于父节点的。这样,对RenderLayer Tree的中序遍历,就会实现将页面元素从后向前渲染。每一个RenderLayer都调用RenderObject的Paint完成对这个节点的绘制。
GPU加速合成
在以上的流程中,并没有使用GPU,接下来的合成阶段GPU才介入。这个过程叫做GPU加速合成。在传统的软渲染中,所有的RenderLayer公用一个GraphicsContext。也就是说,所有的绘制在同一张BitMap上进行(半透明的Layer需要先绘制到一张单独的bitmap上再合成)。这种渲染模式有两个弊端:
1、在同一个脏矩形内,如果一个RenderLayer发生了变化,所有的RenderLayer都必须重新绘制一遍。
2、任务必须是串行的。
GPU合成的使用,可以 很好的解决以上两个问题。基本思路是将RenderLayer渲染到单独的bitmap上,然后将这些bitmap作为OpenGL的Texture,传送给GPU。通过GPU将这些Texture合并到一起。当一个RenderLayer发生变化之后,不需要重新绘制其他Layer,只绘制发生变化的Layer,然后再合成一次即可。
当然,每个RenderLayer分配一张bitmap会消耗大量的内存,这里需要对RenderLayer进行再次的合并,成为GraphicsLayer。有下列特点的RenderLayer会有独立的GraphicsLayer:
1> 有3D或者透视属性的Layer。
2> 使用加速解码属性的<video>标签Layer。
3> 使用3D context(WebGL)或者加速2D context属性的<canvas>标签Layer。
4> Composited Plugin Layer
5> 带有透明度动画或者坐标转换动画CSS的Layer
6> 使用加速CSS过滤器的Layer
7> 需要进行裁剪或者反射的Layer
8> 顶层Layer。
每个GraphicsLayer都有自己的GraphicsContext,也就是一张独立的位图。这样,GraphicsLayer在渲染时实际就是调用它所包含每一个RenderObject的绘制函数,并提供一个GraphicsContext。让每一个RenderObject将自身内容绘制到这个GraphicsContext中即可。
绘制完毕后,GraphicsLayer内容会被上篇介绍的架构,作为Texture通过Command Buffer传送至GPU进程。最终调用OpenGL或者DirectX接口绘制到窗口不同的四边形上,完成合成。由于这个过程完全并行,且很大程度得发挥了GPU的性能优势。所以起到了加速的效果。
分割优化
对于很长的网页,例如新浪,微薄等等,只需要绘制显示出来的那部分。在软渲染的方法中,由于目标bmp只有一张,大家共用。因此,在往这张bmp上画的时候,可以很容易的做出裁剪,超出bmp的部分不被绘制就可以了。但是在GPU加速合成的方法里,需要在绘制GraphicsLayer时,对GraphicsLayer进行裁剪。然后在传送到GPU中。问题出现了,如何对GraphicsLayer进行裁剪?如果恰好裁剪到屏幕边缘,那就意味着,每次混动屏幕,都需要重新绘制GraphicsLayer,然后重新传送给GPU。这样做,效率很低。
解决方案:把大的GraphicsLayer切割成小的Tiles,每个Tile的大小是256 * 256。渲染和提交时,只提交包含或者部分包含在视野内的Titles。这样,只有滑动过tile边界时,才重新提交新进入视野tile,否则,只发一个通知到GPU,让其改变贴图坐标即可完成屏幕滚动。
多线程合成器
从以上分析,我们可以看出,合成过程实际上是比较独立的。因此Chromium将合成部分单独抽出为cc模块。并且为合成操作开启了单独的线程。这样,在render进程中就存在了两个用于渲染的线程,main thread 和 compositor thread。在主线程中,维护了一棵Layer树(LayerTreeHost),管理了TiledLayer,在compositor线程,维护了同样一颗LayerTreeHostImpl,管理了LayerImpl,这两棵树的内容是拷贝关系。因此可以彼此不干扰,当Javascript在主线程操作LayerTreeHost的同时,compositor线程可以用LayerTreeHostImpl做渲染。当Javascript繁忙导致主线程卡主时,合成到屏幕的过程也是流畅的。
两棵树的同步是在compositor线程中进行的,由cc::Scheduler完成。同步的具体内容见代码:
Layer::pushPropertiesTo
在同步的过程中,需要将主线程锁住,但是由于同步内容不多,这个过程比较快。
为了实现防假死,鼠标键盘消息会被首先分发到compositor线程,然后再到主线程。这样,当主线程繁忙时,compositor线程还是能够响应一部分消息,例如,鼠标滚动时,加入主线程繁忙,compositor也会处理滚动消息,滚动已经被提交的页面部分(未被提交的部分将被刷白)。
为了实现多线程调度,从将Layer绘制到bitmap到bitmap以Texture的形式传送给GPU,过程比较复杂,下面用堆栈的形式展开看一下:
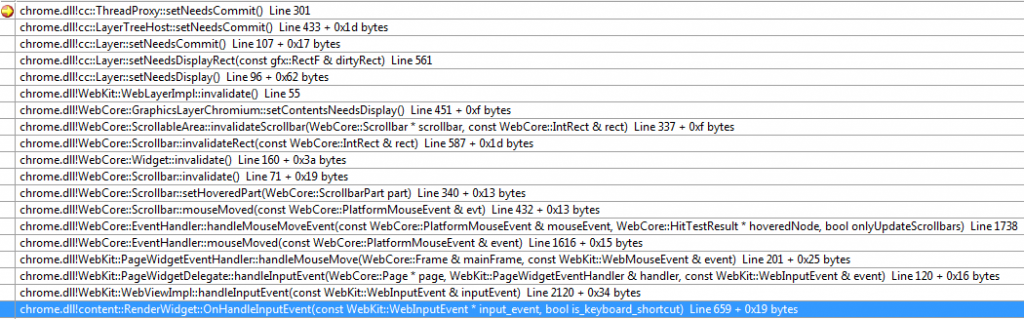
首先,当页面发生变化时,通过webkit层层调用,会调到cc::ThreadProxy::setNeedsCommit,来抛出一个在compositor线程执行的task ThreadProxy::setNeedsCommitOnImplThread

在这个task中调用到cc::ThreadProxy::scheduledActionBeginFrame,再向main thread Post 一个Task cc::ThreadProxy::beginFrame

这个Task会执行内核的绘制,将内容画到一张贴图上,并将这张贴图的指针存到一个cc::ResourceUpdateQueue中。然后再向compositor抛出一个Task cc::ThreadProxy::beginFrameCompleteOnImplThread
![]()
在本线程中再抛出一个Task cc::ResourceUpdateController::onTimerFired
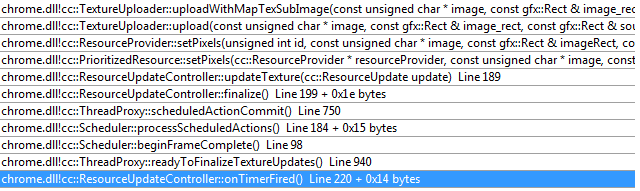
在最后的调用中,由TextureUploader将贴图内容复制到Command Buffer的共享内存中,发送给GPU。从以上过程可以看出,Layer的渲染结果只被拷贝了一次。那就是在TextureUploader中拷贝到共享内存的过程,其他的传递过程都是通过指针进行的。