原文链接:http://gameprogrammingpatterns.com/bytecode.html
意图
通过将数据编码成虚拟机的指令,为行为带来数据适应性。
动机
做游戏很有意思,但是不容易。现代游戏需要大量复杂的代码。主机厂商和App市场的审核人员有一套很严格的质量标准,可能一个小小的崩溃bug就会让你的游戏上不了线。
同时,我们确实希望压榨平台的性能。游戏推动着硬件的发展,我们必须通过变态的优化来保持竞争力。
为了同时满足高适应性和性能要求,我们选择了像C++这样的重量级语言,既有底层语言的灵活性,又能够在大多数硬件和系统上避免bug,或者至少限制bug产生。
我们为有这样的能力而骄傲,但是它是有代价的。一个有经验的码农需要经过多年的严格训练,而且,你还需要注意控制代码库的规模。大游戏的编译时间差距很大,时间短的就像:“来一杯咖啡”,而时间长的就像:“亲手烘培好咖啡豆,细细研磨成粉,蒸馏成咖啡,把牛奶发泡,然后在咖啡泡沫中练习你的拉花艺术”。
在这些挑战的基础上,对于游戏来讲,还有一个很苛刻的评价标准:有趣。玩家希望得到新奇并且平衡的游戏体验。这就需要不断的迭代才能实现。但是如果每次修改都需要程序员纠缠在那些底层代码中,还要等待冗长的编译时间,这会扼杀你的创造力。
回合制战斗
让我们来看一个魔法战斗的例子。一对女巫在场上相互用魔法攻击对方,知道一个胜出。我们可以用代码去定义这些回合,但是这也意味着每次修改,都需要工程师的参与。当设计师想修改一点点数值,找找感觉,他们都必须重新编译整个游戏,重新启动,回到战斗中。
就像今天大多数游戏一样,我们在发布游戏之后仍然需要更新,可能是修复bug或者添加新内容。如果这些回合都是写死的,更新就意味着重新打包游戏的可执行文件。
让我们想得更远一些,我们也要支持mod。我们希望玩家能创造他们自己的回合。如果都是用代码实现的,那这些mod开发者需要一条完整的工具链去编译这个游戏,那我们就需要公开源代码。更糟糕的是,如果他们的回合有bug,可能导致其他玩家机器上的游戏崩溃。
数据>代码
现在很清楚了,使用引擎代码去实现,并不是一个正确的选择。我们需要用安全沙盒将回合代码同游戏核心隔离开来。我们希望他们易修改,易加载,同可执行程序部分在物理上进行隔离。
我不知道你怎么想的,我觉得这听起来像是数据。如果我们在游戏中的单独文件中定义一些行为,并且在引擎中可以通过某些方法加载和“执行”,目的就达到了。
只需要制定这些数据所要“执行”的意义。那么如何在用文件中的一些字节去表达行为呢?有几种办法。我想,我们可以通过比较另外一个Gof的模式——Interperter模式,来了解这个模式的优点和缺点。
Interpreter 模式
这个模式我可以写一整章,但是另外4个哥们已经帮我做了(GOF)。所以我在这里只插入一段简述。从一种你想执行的编程语言开始。例如,它支持像这样的数学表达式:
|
1 |
(1+2)*(3-4) |
然后,选取表达式的各个部分,和各个语言语法,把他们填入一个对象,每一个数字都是一个对象:
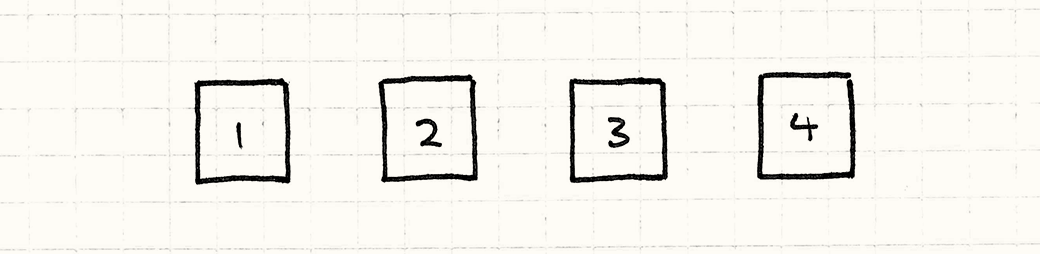
基本上,他们就是对数字的一个简单包装。运算符也被当作对象,他们维护了各自的运算数。如果你留意括号和优先级,这个表达式会被很神奇地变成一棵树,像这样:
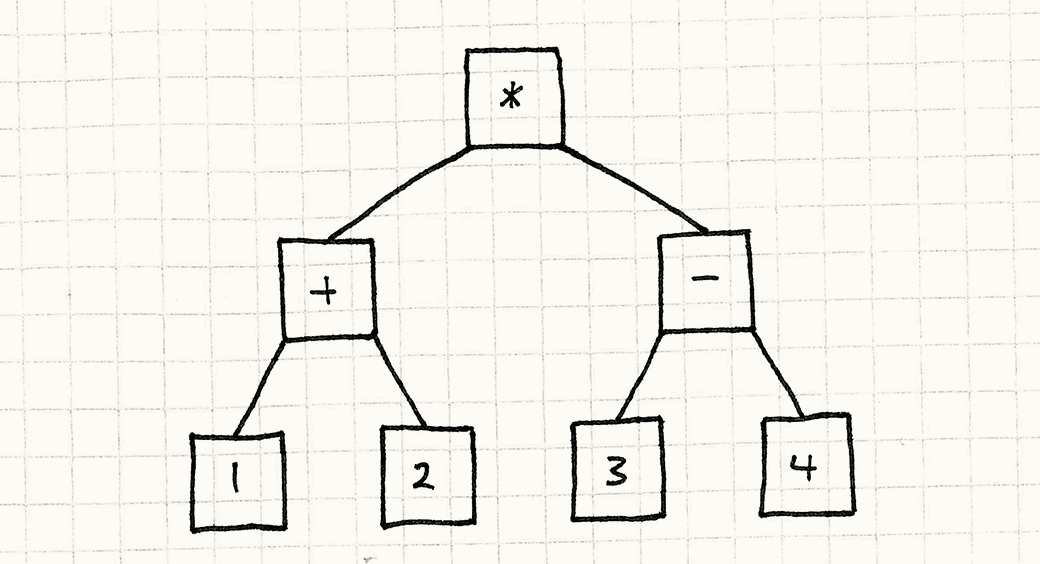
Interpreter模式不是要去创建这棵树,而是要执行它。它的工作很清楚。每一棵树都有它的表达式或者子表达式。按照面向对象的做法,我们让每一个表达式自己进行运算。
首先,我们定义一个接口,让所有的表达式去实现:
|
1 2 3 4 5 6 |
class Expression { public: virtual ~Expression() {} virtual double evaluate() = 0; }; |
然后,我们去定义语法中所有的表达式类型,去实现这个接口。最简单的就是数字类:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class NumberExpression : public Expression { public: NumberExpression(double value) : value_(value) {} virtual double evaluate() { return value_; } private: double value_; }; |
单个数字的表达式基本上等于它的值。而加法和乘法就稍微复杂一些,因为它包含了子表达式,它需要递归得去访问他们的子表达式,就像这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class AdditionExpression : public Expression { public: AdditionExpression(Expression* left, Expression* right) : left_(left), right_(right) {} virtual double evaluate() { // Evaluate the operands. double left = left_->evaluate(); double right = right_->evaluate(); // Add them. return left + right; } private: Expression* left_; Expression* right_; }; |
很简洁吧?只需要一些简单的类,就可以很直接得表现复杂的运算关系。我们只需要创建正确的对象,把它们写在正确的位置。
这是一个小而美的模式,但是也有一些问题。从示意图中我们可以看出,有大量的方块和他们之间的箭头。代码被形象化之后,就是一堆用分型树一样组织起来的小对象。它们有一些讨厌的特点:
1.从磁盘上加载这些表达式,需要实例化很多小对象。
2.链接这些对象的指针占用了大量额外的内存,一个只有32bit的对象,用这种表达方式至少需要68bit。
3.通过指针访问自表达式,就是在谋杀你的数据缓存。同时,每一次虚方法的调用也是对你指令缓存惨无人道的侵害。
总之,就是慢!这就是为什么大多数编程语言不用Interpreter模式,因为它既慢又耗内存。
机器代码,虚拟的
在我们的游戏中,玩家的计算机并不是在运行时区解析C++的语法树,而是我们事先编译成了机器码,CPU就是在运行这些机器码。机器码又什么特点呢?
- 它密集、连续,连续不断的二进制数据,没有一个bit是浪费的。
- 它们是线性的,一个接一个地执行,不会在内存中跳来跳去(当然,除非你控制它这么做)
- 它是底层的,每一个指令只做很小的一件事情,而把它们组合起来就会变得很有意思。
- 它快速,在硬件中运行如风。
哎呦,听起来不错噢,但是我们不想直接使用机器码,这样会导致安全问题。我们既需要机器码的性能,又需要Interpreter模式的安全性。
如果我们不直接加载和运行机器码,而是定义一个我们自己的虚拟机器码,会怎么样?我么可以写一个小的模拟器, 它会像机器码一样——密集,线性,底层——但是,也通过沙箱把它们限制在游戏的范围内,达到安全的目的。
我们把这个小模拟器叫做虚拟机(简称VM),里面跑的代码就是bytecode.我们就得到了一个又很强适应性,并且已用的数据定义方式。而且,它又很好的性能,和跟Interpreter模式媲美的可解释性。
这听起来很唬人,这一章剩下的内容,我会告诉你,如果你把功能尽量简化,那是可以实现的。即使最后你不用这个模式,你也会更好的理解像Lua这种用它实现的语言。
模式
指令集定义了一些底层的操作。一个指令集被编码成一个系列的二进制码。虚拟机每次执行一条指令,用一个栈保存住临时使用的数据。把这些指令组合起来,就可以定义更高层级的行为了。
什么时候用
这是本书最复杂的一个模式,不是简单地扔进你的游戏就可以用。当你的游戏有大量的行为需要定义,而你使用的语言有因为这些原因不适用:
- 太底层,写起来既枯燥又容易出错。
- 因为编译时间长或者其他工具上的问题,导致生成时间太长。
- 代码太危险,需要非常慎重地定义以保证不破坏游戏,你需要让它们运行在沙盒中。
当然,这个列表对很多游戏都适应。谁不希望自己的游戏更快更安全?然而这不是免费得来的。Bytecode比原生代码要慢一些,所以它不太适合游戏引擎中对性能要求很高的部分。
记住
创建你自己的语言或者系统中的系统很有有活力。我会做一个最简单的例子,但是现实中,会变的复杂的多。
每次我见到有人要定义一种语言或者脚本系统,它们都会说:“别担心,它会很小”,然后,必然得,他会加入越来越多的功能,直到变成一个完整的语言。
当然,做一个完整语言也没什么错。只是你要确认那是你想要的。否则就要小心地控制你bytecode所能表达的范围。在失控之前打好预防针。
你需要一个front-end
底层语言又很好的性能,但是二进制的bytecode格式并不能让你的用户进行编辑。我们把行为从代码中提取出来,就是为了能够用更高级的语言表达。如果C++底层到让用户像写汇编一样进行编码,那就不能代表先进生产力。
就像GOF书中的Interpreter模式一样,希望你有生成bytecode的方法。通常,用户用高级格式定义它们的行为,然后通过一个工具转换成我们虚拟机能够理解的bytecode。换句话说,就是编译器。
我直到,这听起来很吓人。所以我先把坏话说在前头。如果你没有做编辑器的资源,那bytecode不适合你。但我们后面会看到,并没有你想象的那么坏。
你会想念你的调试器
编程很难。我们知道我们希望机器做什么,但是我们不能保证总是能够得到正确的结果——我们会写bug。为了解决这些bug,我们攒了很多工具区帮助我们理解代码到底错在哪里了。还有如何修正。我们有调试器,静态分析,反编译器,等等。所有的这些工具都是为已经存在的语言设计的,而不是机器码或者其他更高级的语言。
当你定义自己的bytecode虚拟机时,就会失去这些工具。当然你可以把你的虚拟机挂上调试器,但是它只会告诉你虚拟机本身干了什么,而不是你的bytecode干了什么。自然,它就不能帮助你通过bytecode反推会你编译前的高级语言。
如果你定义的行为比较简单,你可以暂时忍受没有工具帮你debug的现实。随着你的内容越来会越多,就需要投入时间去实现这个功能,让用户能够调试bytecode,知道它们在做什么。这些功能可能不会进入你的游戏,但是会切实的影响你的游戏。
实例代码
通过前两部分的内容,你会好奇怎么实现bytecode。首先,我们需要为我们的虚拟机定义出指令集。在考虑bytecode及其要素之前,我们可以把它们当成API。
魔法API
如果我们直接用C++定义咒语,我们需要什么样的API,取决于我们在游戏中定义了那些咒语。
大多数咒语都是用来改变巫师的状态,所以我们先定义下面几个:
|
1 2 3 |
void setHealth(int wizard, int amount); void setWisdom(int wizard, int amount); void setAgility(int wizard, int amount); |
第一个参数标志哪个巫师,0代表玩家的巫师,1代表对手的。这样,setHealth可以为自己的巫师加血,也可以对对手的巫师造成伤害。这三个方法就包含了几个常见的魔法效果。
如果这些咒语静悄悄地发挥作用,逻辑上没有问题,但是会让玩家感觉很无聊。修复一下:
|
1 2 |
void playSound(int soundId); void spawnParticles(int particleType); |
这些不影响游戏过程,但是会提升玩家的体验。我们可以加入一些更多的效果,像震屏,动画等等,但是作为开始,这已经足够了。
魔法指令集
让我们看看如何把这些需要编程使用的API编程可以控制的数据。从小到大,一步步展开。现在我们先不考虑参数,先只考虑玩家用set__函数用在自己巫师身上,并且把状态加到最猛。同样,效果函数也只是播放一个写死的声音和粒子效果。
这样,一个咒语就变成了一系列指令。我们用枚举定义一下这些操作,每一项都代表着一个操作。
|
1 2 3 4 5 6 7 8 |
enum Instruction { INST_SET_HEALTH = 0x00, INST_SET_WISDOM = 0x01, INST_SET_AGILITY = 0x02, INST_PLAY_SOUND = 0x03, INST_SPAWN_PARTICLES = 0x04 }; |
我们把这些枚举值存在一个数组里,就相当于把咒语编码成了数据。这个枚举值很容易用数据位来表达。也就是说,我们把咒语编程了一串bytes,bytecode就来了。
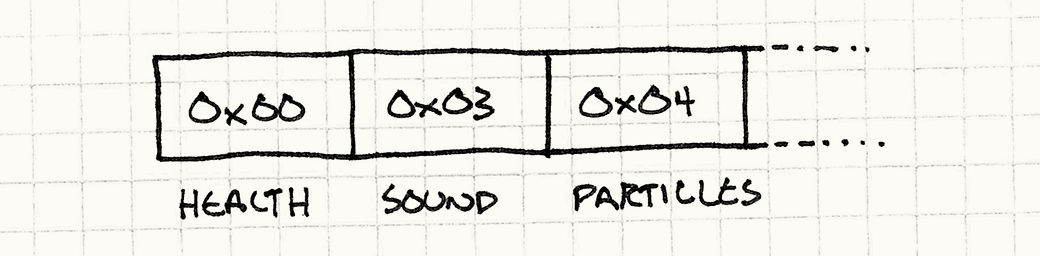
执行一条指令,就是把它通过分发,去执行相应的API方法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
switch (instruction) { case INST_SET_HEALTH: setHealth(0, 100); break; case INST_SET_WISDOM: setWisdom(0, 100); break; case INST_SET_AGILITY: setAgility(0, 100); break; case INST_PLAY_SOUND: playSound(SOUND_BANG); break; case INST_SPAWN_PARTICLES: spawnParticles(PARTICLE_FLAME); break; } |
通过这种方法,我们就在指令和数据之间架起桥梁。我们可以把这个包装成一个简单的虚拟机:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class VM { public: void interpret(char bytecode[], int size) { for (int i = 0; i < size; i++) { char instruction = bytecode[i]; switch (instruction) { // Cases for each instruction... } } } }; |
写下这些代码,这就是你的第一个虚拟机。不过,它并不完整。我们还不能定义那些作用在敌人巫师身上的咒语,也不能削减巫师状态。只能播放一个声音!
为了让它更像是一种实际语言,我们需要引入参数。
栈虚拟机
如果要执行一个复杂的表达式,你要从最近的子表达式开始。计算这个字表达式,并把计算结果以参数的形式传递给它的父表达式。这些参数一直保留到整个表达式计算完毕。
Interpreter模式用一棵对象树来表示表达式,但是我们希望把指令展开成指令列表,得到更快的运算速度。而且,我们要确保子表达式的值流向父表达式。如果把指令展开,就需要用控制指令顺序。就像CPU的那样,用栈。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
class VM { public: VM() : stackSize_(0) {} // Other stuff... private: static const int MAX_STACK = 128; int stackSize_; int stack_[MAX_STACK]; }; |
虚拟机维护了一个数据栈。在我们的例子当中,指令操作的都是数,所以我们用一个简单的int数组来存储。如果指令之间需要传递任何一bit数据,都需要通过这个栈。
如名字所示,数值会被压入栈,然后弹出栈,所以我们再加入一对方法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
class VM { private: void push(int value) { // Check for stack overflow. assert(stackSize_ < MAX_STACK); stack_[stackSize_++] = value; } int pop() { // Make sure the stack isn't empty. assert(stackSize_ > 0); return stack_[--stackSize_]; } // Other stuff... }; |
当一个指令需要接受参数的时候,就从栈中弹出数据,像这样:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
switch (instruction) { case INST_SET_HEALTH: { int amount = pop(); int wizard = pop(); setHealth(wizard, amount); break; } case INST_SET_WISDOM: case INST_SET_AGILITY: // Same as above... case INST_PLAY_SOUND: playSound(pop()); break; case INST_SPAWN_PARTICLES: spawnParticles(pop()); break; } |
为了把数值放在栈里,我们需要另外一个指令:literal。它代表了一行数据。但是数据放在哪?
办法就是利用我们的指令就是一些数据位这个优势——可以把数值直接放在指令数组中。我们定义另一个指令:
|
1 2 3 4 5 6 7 |
case INST_LITERAL: { // Read the next byte from the bytecode. int value = bytecode[++i]; push(value); break; } |
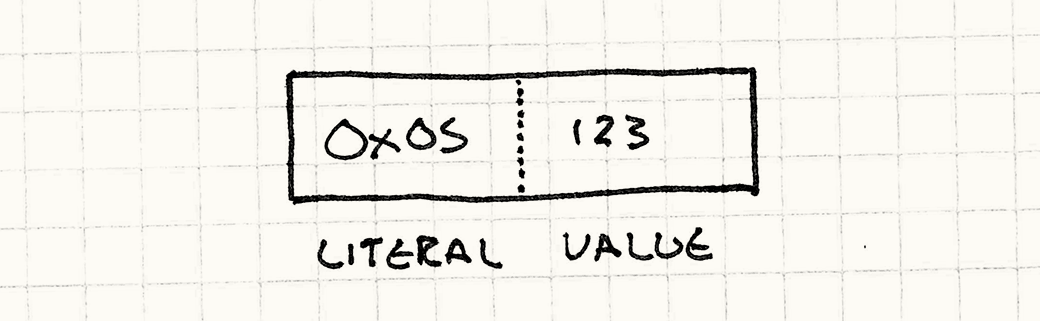
我们从bytecode流的下一个位置,作为数据读取出来,压入堆栈。
现在把几个指令放在一起,让我们感受一下指令和栈式如何协作的。开始时,栈是空的,指令指针放在指令的前端:

第一步,我们执行第一条INST_LITERAL。从bytecode(0)的下一个位置读取数据,并压入栈:

然后执行第二个INST_LITERRAL,读取10并压入栈:

最后,执行INST_SET_HEALTH。从栈中弹出10,作为加血量,弹出0作为巫师ID。然后调用setHealth()并传入这些参数。
哒哒!我们用一个咒语给巫师加了10点血。现在我们有足够的适应性,可以给巫师加任意多的血量。也可以播放不同的音效和粒子。
但是,我们仍然感觉这是数据,而不是函数。例如,我们不能为巫师增加一半血量。我们的设计师希望能够定义规则,而不是数据。
行为=组合
如果我们把我们的虚拟机看做是一种编程语言,现在我们支持的就只有几个内置函数和常量参数。如果想让bytecode更像行为,我们还差了组合。
我们的设计师希望用他们感兴趣的方式去定义表达式。举个简单的例子,他们希望用一个咒语去控制差额的血量,而不是控制到某个血量。
这就需要了解当前的血量是多少,我们已经有了写入状态的函数,现在需要添加读取状态的函数:
|
1 2 3 4 5 6 7 8 9 10 |
case INST_GET_HEALTH: { int wizard = pop(); push(getHealth(wizard)); break; } case INST_GET_WISDOM: case INST_GET_AGILITY: // You get the idea... |
可以看到,它们可以双向操作栈了。可以弹出一个参数去决定读取哪个巫师的状态,然后得到它的状态,并压入栈。
这样我们就可以把巫师的状态写入到任何位置,我们可以把一个巫师的敏捷值设置成它的智力值,也可以写一个奇怪的咒语,把一个巫师的血量设置成它对手的血量。
好一点了,但是还不够。下一步我们需要数学了。是时候让我们的虚拟机宝宝学习1+1了。我们要加入更多的指令。从现在开始,你可以试着接手,去想象一下应该是什么样子。这里我只写一个加法:
|
1 2 3 4 5 6 7 |
case INST_ADD: { int b = pop(); int a = pop(); push(a + b); break; } |
就像其他的指令一样,它弹出两个值,做一个简单的操作,然后把结果压回栈里。目前每一个指令都增加了一点点表达能力,但是对我们来说,已经是一个巨大的飞跃了。不是很显著,但是我们已经处理所有复杂的,深度嵌套的表达式了。
让我们做一个再复杂一点的尝试。希望根据玩家巫师的智力和敏捷的百分比,为巫师加血。代码如下:
|
1 2 |
setHealth(0, getHealth(0) + (getAgility(0) + getWisdom(0)) / 2); |
你可能觉得我们需要新的指令去表达,但是由于有了栈,我们可以这样做:
- 获取巫师的血量,并记住。
- 获取巫师的敏捷,并记住。
- 智力同理。
- 把后面两者架起来,并记住结果。
- 把两者的和除以2,并记住。
- 把上面的结果加到巫师的血量上。
- 把最终的血量设置到巫师身上。
看到这些“记住”,“获取”的字眼了吗?每一个“记住”都代表了压栈,每一个“获取”都代表出栈。这样我们就可以很容得翻译成bytecode了。例如,第一步获取巫师当前的血量:
|
1 2 |
LITERAL 0 GET_HEALTH |
这点bytecode就把巫师的血量压入了堆栈。如果我们把每一句都翻译出来,就会得到一堆bytecode。为了给你一个指令如何组合的印象,我们下面会写出来。
为了显示出栈是如何变化的,我们假定巫师现在的状态是:血量45,敏捷7,智力11.每一个指令的后面是执行这句指令后栈的状态,最后面是简单的解释:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
LITERAL 0 [0] # Wizard index LITERAL 0 [0, 0] # Wizard index GET_HEALTH [0, 45] # getHealth() LITERAL 0 [0, 45, 0] # Wizard index GET_AGILITY [0, 45, 7] # getAgility() LITERAL 0 [0, 45, 7, 0] # Wizard index GET_WISDOM [0, 45, 7, 11] # getWisdom() ADD [0, 45, 18] # Add agility and wisdom LITERAL 2 [0, 45, 18, 2] # Divisor DIVIDE [0, 45, 9] # Average agility and wisdom ADD [0, 54] # Add average to current health SET_HEALTH [] # Set health to result |
如果你逐句仔细观察栈的状态,你会发现数据就像有魔力一样地流过。从压入巫师的索引开始,到我们调用SET_HEALTH设置巫师新的血量为止,这个索引一直在栈的底部。
虚拟机
我可以继续做下去,添加越来越多的指令,但是我觉得最好到此为止。我们已经得到了一个虚拟机,让我们可以用简单,紧密的数据格式,去定义一系列各种各样的行为。虽然像“bytecode”,“虚拟机”这些词听起来挺唬人,其实你可以把它们理解成像栈,循环,switch语句一样简单的概念。
还记得我们另外一个目的,沙箱安全吗?现在你可以看到虚拟机是如何实现的。很明显,我们已经达到目的了。bytecode不能干什么出格的事情,也不能改变游戏引擎的其他部分,因为我们只定义了一少部分可用的指令,与游戏的其他部分无关。
我们可以通过控制栈的大小来控制内存的用量,只要我们小心,不要溢出即可。甚至我们可以控制运行时间。在指令循环中,我们可以跟踪执行了多少指令,如果超越了某些限制,我们可以把剩余的释放掉。
现在只剩下一个问题:如何创建bytecode。目前我们只能手动把伪代码翻译成二进制的bytecode。除非我们闲的蛋疼,否则不会这么做。
施法工具
我们最初的目标是找到一个高层及的方法,去定义行为,但是,我们目前得到的是一个比C++更底层的表达方式。它有运行时的高性能和安全性,但是对设计者并不友好。
要填上这个坑,我们需要工具。就是一个可以把用户定义的高等级咒语行为,转化成用栈虚拟机运行的底层的bytecode。
这听起来比做一个虚拟机都难,许多程序员在学校里的编译器课程都是好不容易才过的。就学到了,像封面上印着条龙的书中的“PTSD”,或者像“lex”和“yacc”这些词汇。
事实上,编译一个基于文本的语言并没有那么难,虽然在这里讨论有点超纲。但是,你没有必要那么做。我这里所说的需要一个工具——并不一定是那种输入文本文件的编译器。
相反,我建议你创建一个可视化的工具让用户去定义他们的行为,特别是那些不希望有技术门槛的用户。对那些没有经过多年使用编译器经验的人来说,写一些没有语法错误的文本,是很困难的。
你可以创建一个应用,让用户可以通过点击、拖拽小方块、和选择菜单来写脚本。或者任何其他的方式去定义他们想要的行为。
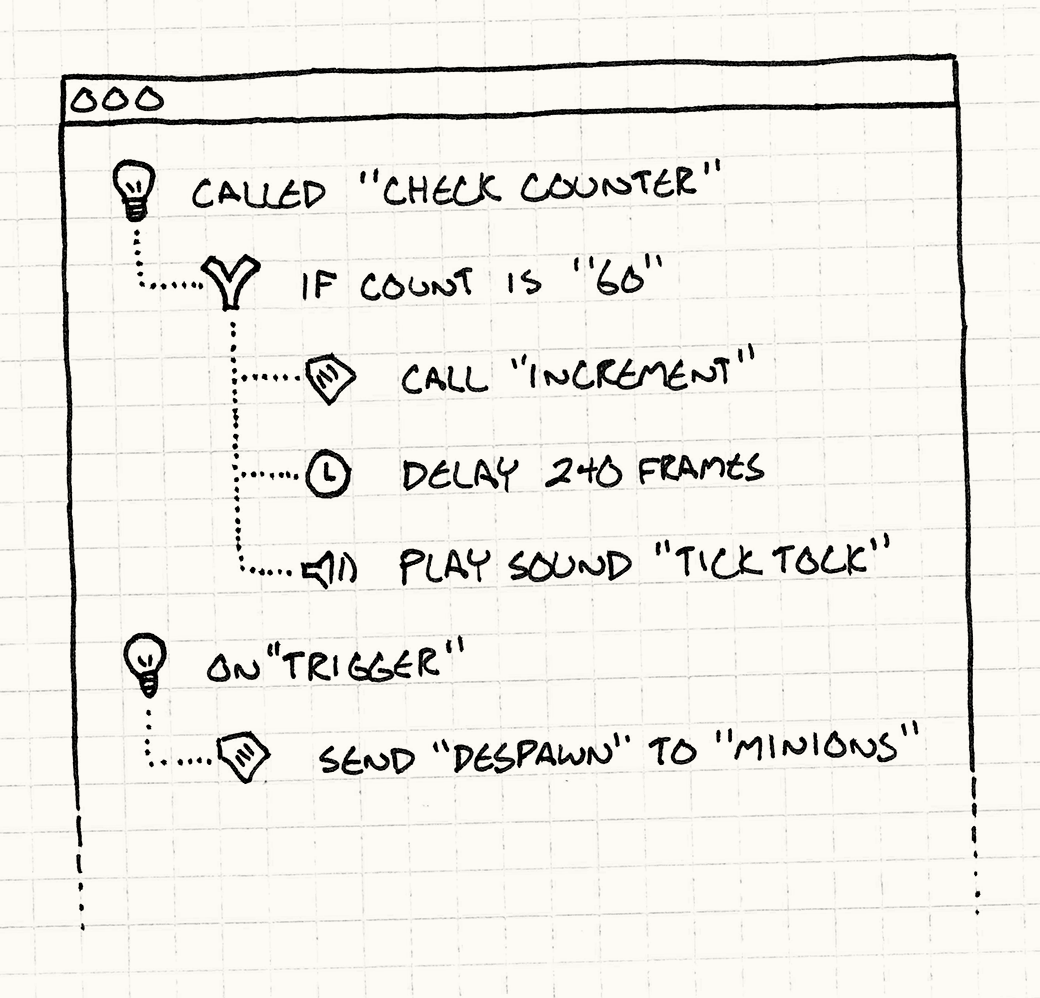
你的UI带来的好处就是让用户不可能写出不可用的程序。你可以通过禁用按钮,提供默认值等方式,避免让他们写出错误的代码,确保每一刻他们提供的代码都是可用的。
这样可以把你从为一种小语言定义语法和写解析器的工作中解放出来。但是,我知道你可以据地UI编程也不太爽,这我就没办法了。
这个模式就是有关如何用友好的,高级的方式定义行为。所以你必须注重用户体验。为了让行为能够最终高效的运行,需要把他们翻译成更底层形式。这真的需要一些工作,但是如果你能接受这个挑战,就会得到回报。
设计抉择
我已经尽量缩短这一章的内容了,但是怎么说我们也是在创造一种语言。这是一个开放性的设计课题。一旦把它展开后果不堪设想,你得确保搞起这个来别忘了完成你的游戏。
指令如何访问栈
Bytecode虚拟机分为两种:基于栈的和基于寄存器的。在基于栈的虚拟机中,指令总是操作栈顶的数据,就像我们例子中所示的那样。例如,INST_ADD 指令需要从栈顶弹出两个值,相加,然后重新压入栈。
基于寄存器的虚拟机也有一个栈。唯一的不同是指令可以从栈的底层读取数据。不再需要像INST_ADD指令这样需要弹出两次栈顶数据,它有两个索引,可以直接在栈中读取数据。
1、如果使用基于栈的虚拟机:
- 指令本身很小。因为么一个指令都从栈顶找到参数,你不需要对数据做任何编码。这就意味着,每一个指令都可以很小,只用一个byte即可。
- 代码生成也简单。当你在写编译器或者bytecode输出工具时,就会发现机遇栈的生成器更简单。由于每一条指令都是对栈顶操作,你只需要保证指令的顺序正确,并在他们之间传递参数就可以了。
- 生成的指令更多。每一条指令只能读取栈顶的数据。也就是说生成就像a=b+c这种代码时,你需要分别把b和c压入栈顶,计算结果,在把结果压入栈顶。
2、如果使用基于寄存器的虚拟机:
- 指令更长。因为指令需要栈的偏移值,单条指令就需要更多的数据位。例如Lua中的指令,它就是很有代表性的基于寄存器的虚拟机,一条指令需要32bit,用6bit代表指令类型,其余的代表参数。
- 指令更少。因为每条指令干的事情更多,所以需要的指令就少。从某种意义上说会提高性能,因为你不需要把数据在栈里压来弹去。
那么我们要用哪个呢?我建议用基于栈的。这更容易实现也更容易生成代码。基于寄存器的虚拟机在Lua选择了之后,以更快而著称,但是,这也取决于你具体的指令和虚拟机本身的其他细节。
你有哪些指令
你的指令集定义了bytecode可以表达的范围,并对你的虚拟机性能也有很大的影响。下面是你可能需要的不同种类的指令列表:
- 扩展单元:这一部分是连接虚拟机和游戏引擎的指令,主要做的是用户可以看到的内容。它们控制了bytecode可以表达哪些行为。如果没有它们,虚拟机除了浪费CPU时钟,没有别的用处。
- 内部单元:这些事虚拟机内部的指令,就像索引,数学计算,比较操作符,还有处理栈的一些指令。
- 控制流:我们的例子并没有涉及到,但是当你想定义一些有优先级的,或者有条件的,或者是循环的指令时,就需要控制流了。对于底层语言的bytecode,其实很简单,就是jump。
在我们的循环指令中,我们有一个变量,跟踪我们当前执行的语句在bytecode中的位置。所有跳转指令其实都是修改这个值,从而改变了我们当前在什么位置执行。换而言之就是goto语句。你可以用这个去构建任意一个高层的控制流。 - 抽象:如果你的用户开始定义大量的数据,通常他们会希望复用一些bytecode,从而避免复制粘贴,你可能就需要一种类似于可调用的函数,这样的东西了。
在最简单的情况下,函数并不比一个跳转语句麻烦多少。唯一的不同是虚拟机维护了第二个用于返回的栈。当你执行一个调用的指令时,它会把当前指令的索引压入“返回栈”,然后跳转到被调用的bytecode。当被调用的代码中触发了“return”指令,虚拟机就会从饭回栈中弹出索引,然后跳转到原来的执行位置。
值如何表达
我们的简化版虚拟机只用了一种类型的值,整形。这答案就简单了——这个栈就是一个int栈。如果是一个功能齐全的虚拟机就应该支持各种各样的数值类型:字符串,对象,列表等等。你就需要确定如何在内部存储。
- 单一数据类型:
1> 简单,你不需要担心标记,转换,和类型检查。
2> 你就不能用不同类型的数据了。这明显是个缺点,把不同类型的数据转成一种格式,把数据转化成字符串,想想就蛋疼。 - 标记的变量类型:
这是动态类型语言常用的做法。每一个值有两部分。第一部分标记了一个枚举,表示这个值是什么类型。剩下的数据位的分布就取决于什么类型,就像这样:
1234567891011121314151617enum ValueType{TYPE_INT,TYPE_DOUBLE,TYPE_STRING};struct Value{ValueType type;union{int intValue;double doubleValue;char* stringValue;};};
数值知道它们自己的类型,这种表达方式的好处是你可以在运行时检查这个值得类型。这对你确定某个值是否匹配某种操作非常重要。
这样会占用更多的内存。每一个值都会携带多余的数据位,用来表示类型。对于虚拟机这么底层设计来讲,很小内存差距都会积累的很大。 - 不使用标记的联合体
这种用到了跟前面相同的联合体,但是不附带类型标记。你有一块数据位,可以表达多种类型数据。需要你自己去保证不存储错。
这就是静态语言的通常的内存使用方法。由于在编译期类型系统就可以确定数值的类型了,就不需要在运行时去验证了。
1> 它很严密。你再也找不到比只保存值本身,内存利用率更高的做法了。
2> 它很高效。没有类型标记,也代表了你不需要耗费CPU去做类型检查,这也是静态语言比动态语言高效的原因之一。
3> 它不安全。这是一个真正的问题。一块错误的bytecode,会导致你错误的解析一个值,或者一个像指针一样的数据。最终会导致整个游戏的安全问题甚至崩溃。 - 接口
面向对象的思想给出了一个解决方案,从多种类型的可能中选出一种。那就是多态。一个接口提供几个虚方法,可以做类型测试和转换,如下:
123456789101112131415class Value{public:virtual ~Value() {}virtual ValueType type() = 0;virtual int asInt() {// Can only call this on ints.assert(false);return 0;}// Other conversion methods...};
然后就可以为每一个具体的数据类型定义类了,就像:
12345678910111213class IntValue : public Value{public:IntValue(int value): value_(value){}virtual ValueType type() { return TYPE_INT; }virtual int asInt() { return value_; }private:int value_;};
1> 它是开放的。你可以定义任意的类型,甚至是虚拟机以外的,只要你实现了接口。
2> 它是面向对象的。如果你赞同OOP的基本思想,就会认为这是一条“正确”的路,并且用多态去分发不同类型的行为,而不用通过switch。
3> 它啰嗦。你必须为每一种想要的数据类型定义一个单独的类。注意我们在前面的例子里定义了那么多类型,这里就实现了一个!
4> 它低效。为了达到多态的目的,你必须通过一个指针,这就意味着即使是一个很小的值就像布尔值,数值等都需要用一个在堆中申请的对象包起来。每次你需要访问一个值都必须调用虚方法。
就像在虚拟机中的代码一样,小的性能损失会被积累起来。事实上,这正是我们避免用Interpreter模式的原因,只不过现在问题出现在了数据层,而不是代码层。
如何生成Bytecode
我留了一个最重要的问题放在最后讨论。我们已经介绍过使用和解析bytecode的代码了,现在需要做一些创建bytecode的工作。最典型的做法是写一个编译器,但这也不是唯一的选择。
- 如果你定义的是基于文本的语言
1> 你必须定义一个语法。不论是业余的还是专业的语言设计师都会深刻的意识到这有多难。定义一个语法,让编译器容易理解很容易,让用户用着顺心很难。
语法设计其实是一种界面设计,但是用一串字符去设计界面,就没那么简单了。
2> 你需要实现一个解析器。大家知道这部分比较容易。无论用像ANTLR和Bison这种解析器生成器,或者手动用递归下降写一个,都比较容易动手。
3> 你需要处理语法错误。这是整个过程中最重要也是最难的一部分。当用户出现了语法错误,你理所应当引导他们回到正确的道路上。如果你只知道解析器出现了异常,那给用户提供有用的反馈就不容易了。
4> 它有可能把非技术人员拒之门外。我们程序员喜欢文本文件。喜欢功能强大的命令行工具,我们可以把他们当成乐高积木,可以组合出千变万化的功能。
但是大部分非程序员就不这么看文本了。对他们来说,文本文件就好像一个脾气暴躁的核查员面前的税务表格,即便他们只是忘记了一个分好,也会被吼上半天。 - 如果你定义一个可视化工具:
1> 你必须实现一个用户界面,按钮,点击,拖拽等等。这种想法听起来挺可怕,但我超喜欢。如果你要沿着这个思路走,那就要把设计用户界面当成你的核心工作去做,而不是只当做一个不喜欢的部分糊弄过去。
你得每一点点额外的努力,都会让你的工具更容易,更喜欢被使用,这也直接会让你的游戏中产生更好的内容。如果你研究过那些你喜欢的游戏,你会发现一个顺手的工具就是秘密武器。
2> 出错的可能性更小。因为用户都是一步一个脚印的创建行为,你的工具会帮助用户避免出错。
对基于文本的语言来说,你的工具在用户把写完的文件扔进去之前,是不知道其中的内容的。所以也就很难避免和处理错误。
3> 移植更困难。文本编译器的好处是文本是不依赖系统的。一个简单的编译器只是读取一个文件和输出一个文件。在不同操作系统中移植比较容易。
如果你要创建一个UI系统,你必须选择用那种框架,其中有很多事依赖操作系统的。也有一些跨平台的UI框架,但是他们普遍难于精通,因为他们对任何一个系统来说,都是陌生的。